我还写了本文的英文版 2000X CUDA Speedup via Budget Graphics Card,欢迎阅读。
众所周知,Nvidia的CUDA计算平台可以实现数量惊人的并行运算,因此受各个流行的机器学习框架青睐。为了尝试人工智能,我最近组装了一台机器,配备了一块入门级的GeForce GTX 1060显卡。
该显卡来自于索泰,有1280个CUDA核心,带6 GB的GDDR5显存。

以下是我进行的两个简单测试,略做记录。第一个测试,用C++写的CUDA程序计算两个大数组的浮点加和,得到了两千多倍的加速。第二个是用Keras+TensorFlow写的MNIST手写数字识别,得到了10倍加速。
大数组浮点加和测试
我按照Nvidia开发者博客的CUDA入门文章,An Even Easier Introduction to CUDA,写了一个简单的程序,对两个长度均为100万的单精度浮点数组进行逐元素加和。
CUDA的并行运算方式也就是所谓的SIMT,即单指令多线程。在CUDA的术语中,运行在GPU上的函数称为核(kernel)。为了进行并行运算,CUDA将函数的执行分散到线程块(数量为numBlocks),每个线程块含有若干个线程(数量为blockSize),所有线程块和其中的线程共同组成了线程网格(Grid)。调用函数时,需要在函数名后面用CUDA特有的三重尖括号指定numBlocks和blockSize。
add<<<numBlocks, blockSize>>>(N, x, y);其中N为数组的长度,x为第一个数组,y为第二个数组。
修改其中的numBlocks和blockSize,用nvprof进行性能分析,得到如下测试结果。
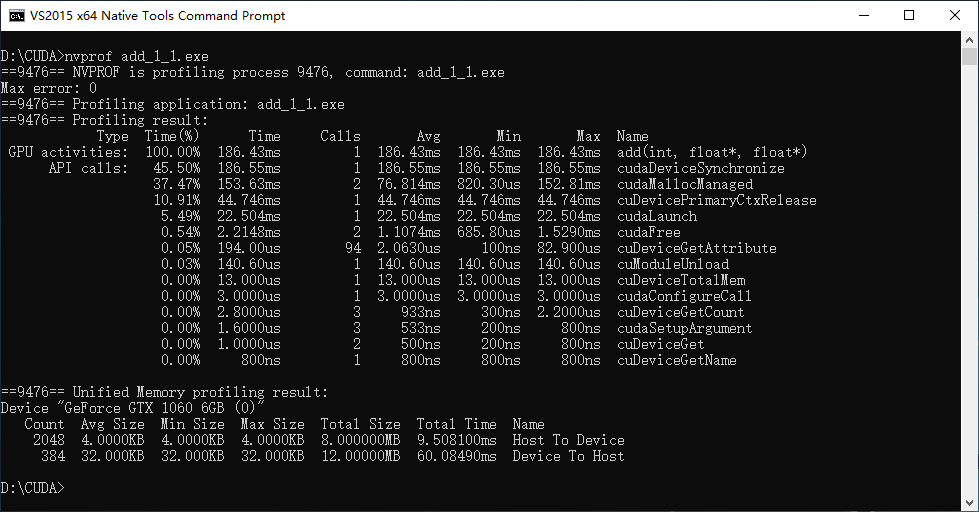
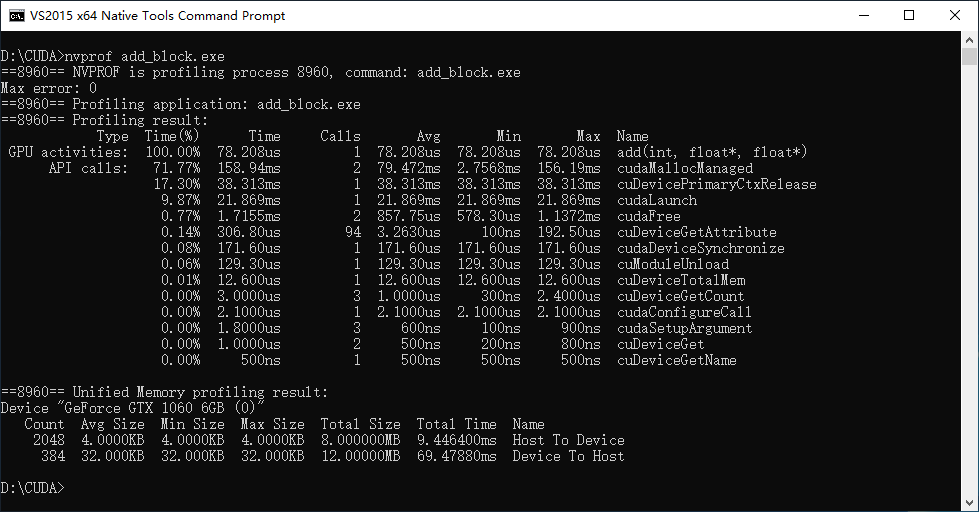
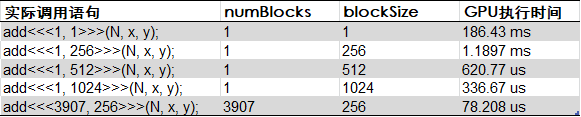
其中最后一行的3907是在调用前通过计算得到的numBlocks。
numBlocks = (N + blockSize - 1) / blockSize;由上面的结果,可以得出,充分利用GPU的多线程并行计算特性后,计算速度提升了惊人的2383倍。
MNIST手写数字识别测试
第二个测试是用Keras进行了经典的MNIST手写数字识别。代码来自于一篇非常深入浅出的文章,Image Classification using Feedforward Neural Network in Keras。
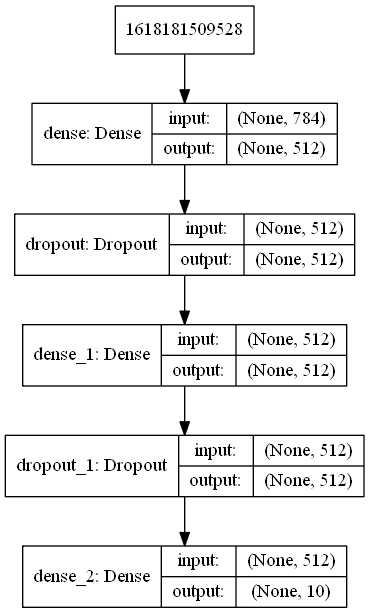
Keras提供了一个非常高层的API,而其底层可以是其他深度学习框架,如TensorFlow。我在同一台电脑上分别安装了CPU版和GPU版的TensorFlow。下面是测试结果。
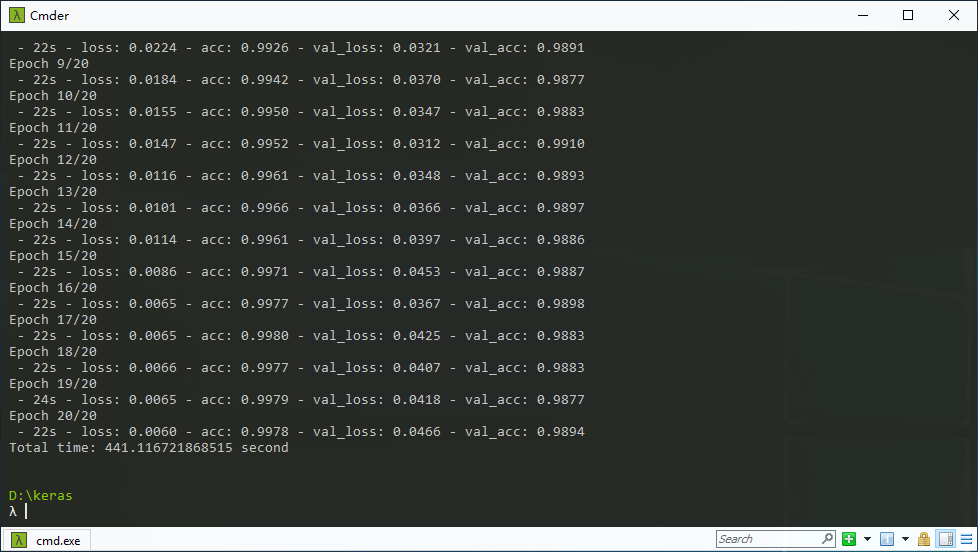
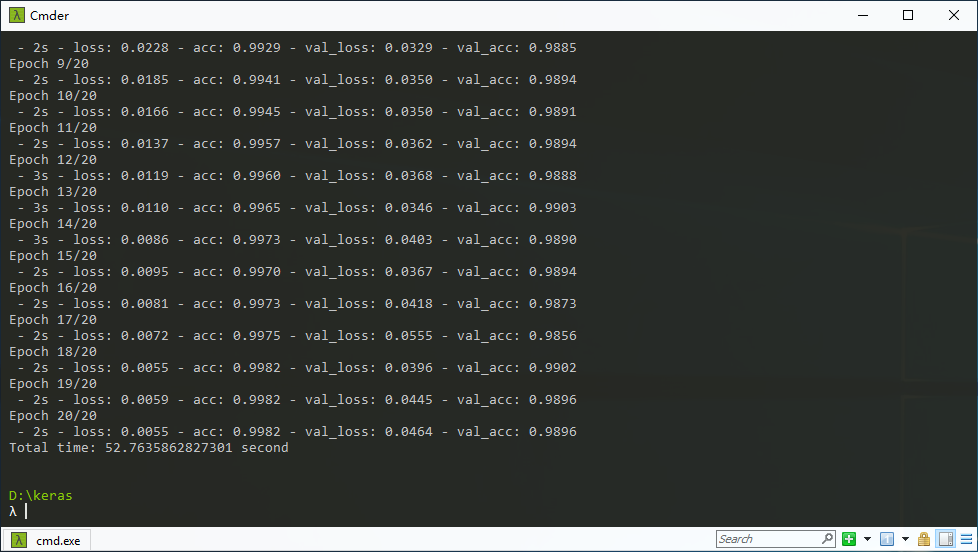

由上图可见,在这个简单的深度网络测试中,通过GPU得到了10倍的加速。
总结
在某些可并行处理的应用中,即使是上一代的入门级游戏显卡,其大量的计算单元(本例中的显卡含1280个CUDA核心)也能得到显著的提升。
笔者身处非常传统的非技术行业,以上知识均为自学,因此难免有遗漏或错误,欢迎各位读者(假装有读者)提出宝贵的建议。